تا به حال شده تصویری از یک متن در اختیار داشته باشید که نتوانید آن را ویرایش کنید؟ می خواهید قسمتی از متن را انتخاب کنید، اما نمی شود. در واقع شما فایلی را در اختیار دارید که حاوی متنی است که به صورت تایپی یا دست نویس است اما امکان ویرایش آن وجود ندارد. در چنین مواقعی ممکن است تصمیم بگیرید دوباره آن متن را تایپ کنید. اما تایپ دوباره کاری زمان بر است. این جا همان جایی است که تکنولوژی OCR به کمک شما می آید.
فناوری OCR یا نویسه خوان نوری به شما کمک می کند تا تصاویر خود را به متن تبدیل کنید. در واقع این تکنولوژی با شناسایی متن موجود در تصویر، متن تایپ شده و قابل ویرایشی را به شما تحویل می دهد. اسناد اسکن شده، فایل های PDF یا اسنادی که توسط دوربین از آن ها عکس گرفته شده است، می توانند با فناوری OCR خوانده شوند. اگر دانشجو هستید، کار تحقیقاتی انجام می دهید و یا به هر دلیلی با تصاویر حاوی متن سر و کار دارید، OCR به کمک شما خواهد آمد.
OCR چیست؟
OCR یا نویسه خوان نوری مخفف Optical Character Recognition یا Optical Character Reader است که در واقع فناوری تبدیل تصاویر به متن است. در این فناوری متن موجود در تصاویر با استفاده از روش های مختلف از جمله الگوریتم های هوش مصنوعی و پردازش تصویر شناسایی شده و تشخیص داده می شود. قبل از بوجود آمدن این فناوری، افراد باید متن های اسکن شده را تایپ می کردند ولی با استفاده از نویسه خوان نوری می توان به متن قابل ویرایش تصاویر دست یافت به طوری که می توان به راحتی متن تولید شده را در نرم افزارهای مختلفی مانند ورد محصول شرکت مایکروسافت ویرایش کرد.
وقتی که به تصویر یک متن نگاه می کنید، می توانید متن آن را بخوانید و موضوع آن را متوجه شوید. تشخیص حروف و اعداد در تصویر برای شما که انسان هستید کار ساده ای است اما رایانه نمی تواند حروف و اعداد را تشخیص دهد و آن را به شکل پیکسل هایی می بیند که مفهومی ندارند. برای اینکه متن موجود در تصاویر توسط رایانه قابل خواندن باشد از OCR استفاده می شود. OCR با استفاده از الگوریتم هایی که دارد می تواند این حروف را تشخیص داده و آن ها را بخواند.
با OCR می توانید موارد زیر را تبدیل به متن کنید:
- مقالات، کتاب ها، مجلات
- بروشورها، کاتالوگ ها، سفارشات
- رسیدهای بانکی، اسناد سازمانی
- خواندن علائم راهنمایی و رانندگی در جاده ها و خیابان ها
- خواندن پلاک خودروها
OCR چگونه کار می کند؟
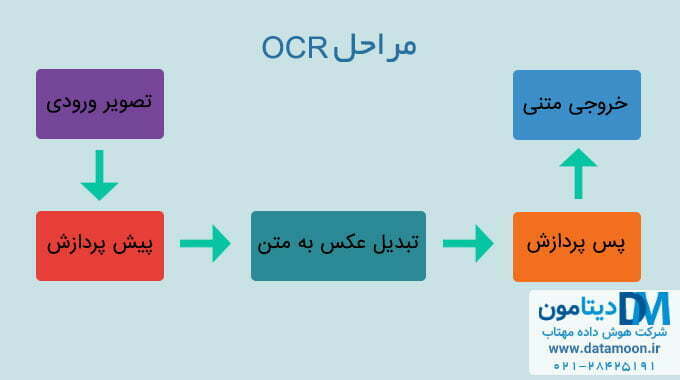
به طور کلی فرایند تبدیل تصویر به متن یا OCR شامل مراحل پیش پردازش، شناسایی حروف در تصویر و پس پردازش است. بعد از اینکه عکس را وارد نرم افزار OCR می کنیم، پیش پردازشی روی آن انجام می شود تا کیفیت عکس بالاتر رود. قسمت های اضافی حذف می شوند و عملیاتی دیگری روی عکس انجام می شود. مثلا ممکن است در هنگام اسکن متن، زاویه ی خطوط در راستای عمود یا افق نباشند در این صورت تصویر به اندازه ی چند درجه می چرخد تا خطوط در راستای مناسبی قرار بگیرند.
علاوه بر این ممکن است حروف یک کلمه اشتباها به هم چسبیده باشند، این حروف نیز طی عملیاتی شکسته و از هم جدا می شوند. همچنین عکس به تصویری سیاه و سفید تبدیل می شود. خطوط از تصویر حذف می شوند. در نهایت عکس آمادگی لازم برای اینکه حروف آن تشخیص داده شود را پیدا کرده است.
در مرحله ی بعد با استفاده از الگوریتم های مطرح در این زمینه و همچنین با در اختیار داشتن داده های کافی برای آموزش الگوریتم، متن موجود در تصویر شناسایی شده و عکس تبدیل به متن می شود. در گام بعدی عملیاتی برای بررسی نتیجه ی خروجی و پس پردازش انجام می شود.
یکی از مراحل پس پردازش می تواند بررسی غلط های املایی کلمات تبدیل شده باشد. می توان از واژه نامه ای برای بررسی اشکالات املایی کلمات استفاده کرد. فرض کنید نرم افزار شما به منظور تبدیل عکس به متن در حوزه ی پزشکی توسعه داده شده است. در نتیجه می توان از واژه نامه ی پزشکی استفاده کرد تا اشتباهات موجود تشخیص داده شود. در نهایت نیز نتیجه به کاربر نشان داده می شود.

چگونه OCR حروف را تشخیص می دهد؟
دو روش برای تشخیص حروف وجود دارد. انطباق ماتریس و استخراج ویژگی ها دو روش مورد استفاده برای تشخیص حروف و اعداد در ocr هستند.
ماتریس انطباق (Matrix matching)
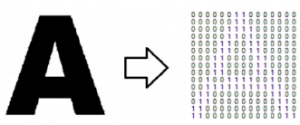
در این روش تصویر یک حرف با تصویر ذخیره شده در پایگاه داده مقایسه می شود و این مقایسه به صورت پیکسل به پیکسل انجام می گیرد. این روش تطبیق الگو نیز نام دارد. زیرا الگوهای دو حرف با هم مقایسه می شوند. این روش برای نوشته های تایپی مناسب است و ابتدا از این روش برای OCR استفاده می شد. در تصویر زیر حرف A را مشاهده می کنید که به ماتریسی از ۰ و ۱ ها تبدیل شده است.

استخراج ویژگی (Feature extraction)
روش استخراج ویژگی که بعدها مورد استفاده قرار گرفت ویژگی های حروف مانند خط ها، دایره های بسته، جهت خط ها و تقاطع آن ها را در حروف در نظر می گیرد و از این طریق اقدام به شناسایی حروف می کند. این ویژگی ها با ویژگی های ذخیره شده ی مربوط به هر حرف مقایسه می شود تا حرف شناسایی گردد.
تکنیک های استخراج ویژگی از بینایی ماشین استفاده می کنند و در واقعی روشی هوشمند برای شناسایی حروف و ارقام محسوب می شوند. در تصویر زیر حرف a را مشاهده می کنید. حرف a انگلیسی از یک دایره ی تو خالی، یک خط در سمت راست دایره و یک کمان در بالای آن تشکیل شده است که وجود این کمان اختیاری است. در واقع این ها سه ویژگی حرف a را می سازند. حال با داشتن این سه ویژگی و مقایسه آن با ویژگی حروف دیگر می توان، حرف a را تشخیص داد.

انواع OCR
- بازشناسی متن های تایپ شده: تصویر متن هایی که در روزنامه، مجلات، کتاب ها و اسناد دیگر به صورت تایپ شده وجود دارند، توسط OCR به متن تبدیل می شوند.
- بازشناسی متن های دست نویس: متن هایی که توسط شخص انسانی و بدون تایپ کردن نوشته شده اند نیز امکان بازشناسی دارند. اما تبدیل این دسته از اسناد به متن کار بسیار دشوارتری است، زیرا نحوه ی نوشتن انسان ها با هم بسیار متفاوت است و تشخیص کاراکترها و حروف در این اسناد مشکل می شود.
متن ها یا به صورت گسسته هستند و یا پیوسته. در متن های گسسته، حروف به صورت جدا از هم نوشته می شوند. این حالت را حتما در پر کردن فرم ها تجربه کرده اید. در حالت پیوسته حروف به صورت پیوسته نوشته می شوند و کلمات و جملات را تشکیل می دهند. OCR حروف گسسته راحت تر از OCR حروف پیوسته است.
کاربردهای OCR
- از فناوری OCR برای تولید نرم افزار پلاک خوان استفاده می شود.
- در فرودگاه برای شناسایی گذرنامه و استخراج اطلاعات آن
- تبدیل تصاویر اسناد به متن برای مثال تبدیل کتاب های اسکن شده یا رسیدها و اسناد مربوط به کسب و کار به متن آن ها
- فراهم کردن امکان جستجو در بین اسنادی که به صورت تصویر هستند. با تبدیل تصاویر به متن می توان به راحتی در بین متن ها جستجو کرد.
- فریب سامانه هایی که از کپچا برای تعیین انسان بودن کاربران استفاده می کنند
- کمک به افراد نابینا و کم بینا برای خواندن متون
- ترجمه ی متن موجود در تصاویر به صورتی که ابتدا عکس تبدیل به متن شده و سپس ترجمه می شود
- تبدیل فایل های PDF به متن
مشکلات OCR در زبان فارسی
در زبان فارسی به علت شکل نوشتاری حروف و شباعت برخی حروف به همدیگر تبدیل متن به عکس دشوار می شود. در ادامه این مشکلات را بررسی کرده ایم.
چسبیده نوشتن حروف
در زبان فارسی حروف یک کلمه به هم می چسبند. برای مثال کلمه ی “فارسی” را در نظر بگیرید. این کلمه دارای حروف چسبیده به هم است و بسیاری از کلمات دیگر در زبان فارسی به صورت چسبیده نوشته می شوند. همین موجب دشواری تشخیص حروف در زبان فارسی است. این مشکل در زبانی مانند زبان انگلیسی وجود ندارد. چون در انگلیسی حروف به صورت جدا از هم تایپ می شوند.
شباهت حروف
در زبان فارسی حروف شبیه به هم مختلفی داریم. مثلا حرف “س” و “ش” و حتی “ص” و “ض” ممکن است در صورت عدم خوانایی کافی با هم اشتباه گرفته شوند. یا مثلا حروف “ر” و “ز” تنها در یک نقطه ی کوچک با هم تفاوت دارند.
منبع۱، منبع۲، منبع۳

 تخفیف ویژه نوروزی
تخفیف ویژه نوروزی