مجله
ده الگوریتم یادگیری ماشین که مبتدی ها باید آن ها را بدانند
امروزه، بسیاری از کارهایی که در گذشته با دست و توسط نیروی انسانی انجام می شده اند، به صورت خودکار و توسط ماشین ها انجام می شوند. یادگیری ماشین، همان چیزی است که به ماشین ها این امکان را می دهد که بتوانند شطرنج بازی کنند، عمل جراحی انجام دهند و حتی یاد بگیرند!
ما در دوره ای زندگی می کنیم، شاهد پیشرفت سریع فناوری های مختلف هستیم. هر روز شاهده توسعه ی سیستم ها و ماشین های مختلفی هستیم که می توانند بسیاری از کارها را به صورت هوشمند و خودکار و بدون دخالت انسان ها انجام دهند. الگوریتم های یادگیری ماشین کمک شایان توجهی در این زمینه کرده اند.
الگوریتم های یادگیری ماشین چهار دسته هستند:
- نظارتی (supervised)
- غیرنظارتی (unsupervised)
- نیمه نظارتی (semi supervised)
- یادگیری تقویتی (Reinforcement Learning)
این چهار دسته ی اصلی به دسته های کوچکتری نیز تقسیم می شوند:
- رگرسیون خطی (Linear regression)
- رگرسیون لجستیک (Logistic regression)
- درخت تصمیم گیری (Decision tree)
- الگوریتم SVM
- بیز ساده (Naive Bayes)
- KNN
- K-means
- الگوریتم جنگل تصادفی (Random forest)
- الگوریتم های کاهش بعد (Dimensionality reduction)
- الگوریتم ارتقای گرادیان (Gradient boosting) و الگوریتم AdaBoosting
یادگیری این الگوریتم ها، شما را در مهارت های مربوط به یادگیری ماشین کمک می کند. شما چه یک دانشمند داده باشید و چه یک علاقه مند به حوزه ی یادگیری ماشین، با یادگیری هر کدام از این الگوریتم ها می توانید، پروژه های یادگیری ماشین را انجام دهید. البته اینکه بتوانید پروژه های پیچیده تری را انجام دهید باید تسلط بیشتری بر روی الگوریتم ها داشته باشید. هر یک از الگوریتم هایی که در بالا به آن ها اشاره کردیم در چهار دسته ی نظارتی، غیر نظارتی، نیمه نظارتی و یادگیری تقویتی قرار می گیرند. در ادامه به توضیح مختصری درباره ی هر یک این الگوریتم ها می پردازیم.
۱- رگرسیون خطی (Linear Regression)

الگوریتم رگرسیون به دنبال رابطه ی بین متغیرها می گردد. در مسئله ی رگرسیون ما دو نوع متغیر داریم: متغیر وابسته و مستقل.
مثلا فرض کنید که مسئله ی ما یافتن رابطه ی بین میزان حقوق کارکنان با ویژگی های آن ها مانند تجربه، تحصیلات، سن و موارد این چنینی باشد. در این مسئله، میزان حقوق متغیر وابسته ای است که به سن، تجربه و تحصیلات وابسته است اما سه متغیر دیگر به چیزی وابسته نیستند. در واقع آن ها مستقل هستند. شما با داشتن اطلاعات تعدادی از کارکنان می توانید که پیش بینی کنید وقتی یک کارمند جدید استخدام می شود حقوقش چقدر خواهد بود.
پس می توان گفت که در الگوریتم رگرسیون خطی، رابطه ای بین متغیرهای وابسته و مستقل شکل می گیرد که یک معادله ی خطی خواهد بود: Y= a *X + b
۲- رگرسیون لجستیک
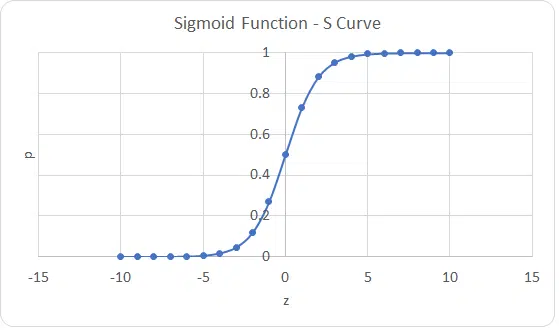
این الگوریتم برای پیش بینی مقادیر گسسته کاربرد دارد. برای مثال مقدار ۰ و ۱ دو مقدار گسسته هستند اگر بازه ی بین آن ها را در نظر نگیریم و در غیر این صورت پیوسته نامیده می شوند. یا زن و مرد بودن نیز دو مقدار گسسته هستند. در این جا هم مانند رگرسیون خطی ما به دنبال رابطه ی بین متغیرها هستیم. فرقی که این الگوریتم با حالت خطی آن دارد این است که مقادیری که به دنبال پیش بینی آن ها هستیم، گسسته هستند نه خطی و پیوسته.
برای مثال فرض کنید که می خواهیم بدانیم فلان نماینده در انتخابات پیروز می شود یا خیر یا اینکه این دانش آموز امتحانات خود را با موفقیت پشت سر می گذارد یا خیر. تمامی این موارد با رگرسیون لجستیک قابل حل است. در مثال قبولی دانش آموز متغیرهای ورودی می توانند مواردی مانند نمره ی میان ترم، نمره ی کلاسی و نمره ی پایان ترم باشند. با داشتن این سه متغیر می توان محاسبه کرد که آیا دانش آموز قبول می شود یا خیر.
۳-درخت تصمیم گیری

درخت تصمیم گیری یکی از الگوریتم های مهم یادگیری ماشین است که در دسته ی الگوریتم های نظارتی و برای دسته بندی (classification) استفاده می شود. این الگوریتم هم می تواند برای پیش بینی مقادیر گسسته و هم پیوسته استفاده شود. این الگوریتم بر اساس مقادیر متغیرها، داده های ورودی را در دو یا چند دسته، تقسیم بندی می کند. درخت تصمیم گیری سعی می کند که بر اساس داده های ورودی، درختی بسازد و دسته بندی را بر اساس این درخت انجام دهد. درختی که در مرحله ی آموزش الگوریتم ساخته می شود برای پیش بینی استفاده می شود. بعد از این هر داده ای که به عنوان ورودی به الگوریتم داده می شود ابتدا با ریشه ی درخت مقایسه می شود و سپس بر اساس نتیجه ی حاصل از این مقایسه با برگ های دیگر نیز مقایسه می گردد تا در نهایت در دسته ی مناسبی قرار بگیرد.
در این الگوریتم می توانیم از مثال پیش بینی درامد بر اساس میزان تحصیلات، جنسیت و سن استفاده کنید. فرض کنید که مقدار درامد برای ما مهم باشد و ما این متغیر را نداشته باشیم ولی به متغیرهای دیگری دسترسی داریم. درختی می سازیم که برای مثال ریشه ی آن جنسیت است. سطح بعدی سن مقایسه می گردد و در سطر آخر تحصیلات. این درختی است که الگوریتم درخت تصمیم گیری آن را ساخته است. حال اگر فرد جدیدی وارد لیست شود و ما قصد پیش بینی درآمد آن را داشته باشیم، ابتدا جنسیت آن در ریشه مقایسه می گردد و در نهایت با مشخص بودن میزان تحصیلاتش وارد یک دسته می گردد.
۴- الگوریتم SVM (Support Vector Machine)

در این الگوریتم تمام داده ها در یک مختصات رسم می شوند. سپس خطوط یا بردارهایی که با استفاده از آن ها دسته بندی انجام می شود این مقادیر را دسته های گوناگون، دسته بندی می کنند. در واقع هدف الگوریتم SVM مشخص کردن خطوطی است که به بهترین نحو بتوانند داده ها را در دسته های مختلف، دسته بندی کنند.
برای مثال این الگوریتم می توان به مسئله ی طبقه بندی دو حیوان سگ و گربه اشاره کرد. برای حل مسئله این مسئله ابتدا مقادیر زیادی از تصاویر گربه و سگ به الگوریتم داده می شود تا مدلی بر این اساس ساخته شود. سپس از این مدل برای پیش بینی عکس های جدید استفاده می شود. اگر عکس گربه ی جدیدی به الگوریتم داده شود، الگوریتم با مدل موجود سعی می کند آن عکس را در دسته ی درست آن قرار دهد و پیش بینی درستی انجام دهد.
۵- الگوریتم بیز ساده

در الگوریتم بیز ساده، فرض می شود که حضور هر یک از متغیرها در یک کلاس به یکدیگر ارتباطی ندارند. حتی اگر واقعا هم متغیرها به هم ارتباط داشته باشند، اما در این الگوریتم این طور فرض می شود که در تولید نتیجه ی خروجی آن ها هیچ ارتباطی با یکدیگر ندارند. برای دیتاست هایی که حجم داده های بسیار بالایی دارند الگوریتم بیز ساده می تواند کارایی داشته باشد. مورد دیگر که باید به آن اشاره کنیم، این است که الگوریتم بیز ساده بر پایه ی تئوری بیز ایجاد شده است. در بیز ساده تمام متغیرها مستقل از یک دیگر هستند و همچنین تاثیر یکسانی در پیش بینی دارند. مثلا در تشخیص اینکه میوه ای سیب است میزان گرد بودن آن تاثیر بیشتری نسبت به قرمز بودن آن ندارد. همه تاثیر یکسان و مساوی دارند.
فرض کنید که یک میوه سیب است اگر قرمز، گرد و قطری حدود ۵ سانتی متر داشته باشد. در الگوریتم بیز ساده فرض می شود که هیچ کدام از این ویژگی ها ارتباطی با هم ندارند حتی اگر واقعا هم ارتباط داشته باشند. در واقع سیب بودن میوه ی مورد نظر، حاصل این ویژگی ها به صورت مستقل است. به همین دلیل این الگوریتم ساده نامیده می شود.
۶- الگوریتم KNN (K-Nearest Neighbors)
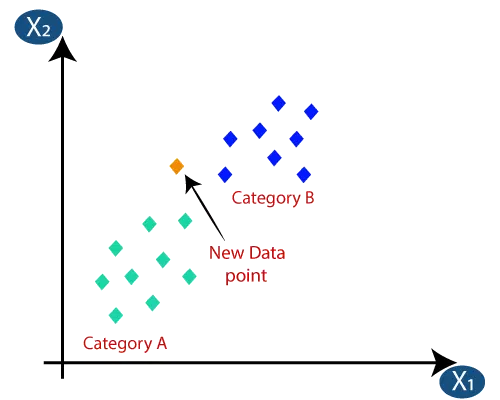
از این الگوریتم می توان در مسائل دسته بندی و رگرسیون استفاده کرد. اما بیشتر برای مسائل دسته بندی استفاده می شود. در این الگوریتم که داده های مشابه در مجاورت هم قرار دارند. برای طبقه بندی داده ی جدید به K همسایه ی مجاور توجه می شود و مشابهت با این همسایه ها محاسبه می شود. یعنی فاصله ی داده ی ورودی جدید با همسایه های مجاورش مقایسه می شود و طبق این فاصله در دسته ی مورد نظر قرار می گیرد. اینکه چه تعداد همسایه تعریف کنیم، نیاز به تکرار الگوریتم دارد انقدر مقادیر مختلف برای K در نظر می گیریم تا خطا به حداقل برسد.
مسائل های مختلفی از KNN در اطراف ما وجود دارند. برای مثال اگر دنبال اطلاعاتی از یک فرد هستید، مسلما یافتن این اطلاعات از افراد نزدیک که او که می توانند خانواده و دوستانش باشند بهتر است.
۷- K-Means

الگوریتم K-Means یکی از انواع الگوریتم های غیرنظارتی است که برای حل مسائل خوشه بندی (clustering) استفاده می شود. در این مسائل دیتاست به خوشه های مختلفی دسته بندی می شود. داده هایی که در هر یک از این خوشه ها وجود دارند همگن هستند و نسبت به داده های موجود در خوشه های دیگر ناهمگن اند.
در الگوریتم K-Means نقاطی به عنوان مرکز هر یک از خوشه ها انتخاب می شوند، نقاط نزدیک به هر یک از این مرکزها در داخل همان خوشه قرار می گیرند. این کار آنقدر تکرار می شود که همه ی داده ها در خوشه های مناسب خوشه بندی شوند.
سوالی که در این قسمت وجود دارد و ممکن است برای شما پیش آمده باشد، تفاوت K-Means و KNN است. KNN برای مسائل دسته بندی استفاده می شود و از نوع نظارتی است اما K-Means برای خوشه بندی استفاده می شود و از نوع غیر نظارتی است.
برای مثال الگوریتم K-Means، حالتی را در نظر بگیرید که فروشگاه اینترنتی می خواهد مشتریان خود را با توجه به رفتار خرید آن ها در گروه های مختلفی، دسته بندی کند. این کار با استفاده از همین الگوریتم امکان پذیر است.
۸- الگوریتم Random Forest

مجموعه ای از درختان تصمیم گیری یک جنگل تصادفی می سازند. ابتدا K نقطه ی تصادفی از بین داده ها انتخاب می گردد و با آن درخت تصمیمی ساخته می شود. سپس K داده ی دیگر نیز به صورت تصادفی انتخاب می شوند و درختی دیگر ساخته می شود و به این ترتیب چندین درخت تصمیم خواهیم داشت که همه با هم یک جنگل را می سازند.
در مرحله ی بعد وقتی که نیاز به پیش بینی وجود داشته باشد و داده ی جدیدی به مدل داده شود، این داده توسط همه ی درخت ها مورد بررسی قرار می گیرد و در نهایت با رای گیری بیشترین رای ای که از این درختان حاصل شده، کلاس مورد نظر خواهد بود.
برای این الگوریتم هم مثالی را در نظر بگیرید که می خواهد تشخیص دهد که نوع یک میوه چیست. ابتدا درخت هایی با داده های ورودی ساخته می شود. هر کدام از این درخت ها میوه را در یک گروه دسته بندی می کنند. در نهایت بیشترین رای، نوع کلاس را مشخص می کند.
۹- الگوریتم کاهش بعد

در دنیای امروز داده های زیادی وجود دارند که توسط شرکت ها و دولت ها مورد استفاده قرار می گیرند. اطلاعات مفید و مهمی در این داده ها وجود دارد که باید از میان این انبوه اطلاعات استخراج گردد. الگوریتم های مختلفی به منظور کاهش بعد وجود دارند که به شما در یافتن اطلاعات مفید از این این داده های عظیم کمک می کنند. درخت تصمیم و جنگل تصادفی از جمله ی این الگوریتم ها هستند.
۱۰- الگوریتم Gradient Boosting و AdaBoosting

این الگوریتم های ارتقا دهنده زمانی کاربرد دارند که حجم عظیمی از داده ها باید در یک پیش بینی با دقت بالا تحلیل شوند. الگوریتم های ارتقا دهنده، چندین الگوریتم مختلف را با هم ترکیب می کنند تا قدرت پیش بینی را افزایش دهند. در واقع با ترکیب چند الگوریتم ضعیف یا متوسط یک الگوریتم قوی ساخته می شود.
نتیجه گیری
می توانید با یادگیری این الگوریتم ها و فهم ساختار آن ها، مسائل یادگیری ماشین را حل کنید. هر چقدر که بر روی این الگوریتم ها مسلط تر باشید، توانایی حل مسائل پیچیده تر را نیز خواهید داشت. همان طور که در مطالب بالا ذکر شد هر یک از این الگوریتم ها توانایی حل مسائل مختص به خود را دارند و یک متخصص علم داده باید بتوانید تشخیص دهد که از هر الگوریتم در چه زمانی استفاده کند.
شما می توانید برای ساخت یک برنامه مبتنی بر هوش مصنوعی مانند نرم افزار پلاک خوان، تشخیص حرکت، تشخیص رنگ و نوع خودرو و مسائل دیگر از الگوریتم های یادگیری ماشین استفاده کنید.