
به سبب رشد سریع شبكه ها و رسانه هاي اجتماعی، افراد زیادی روزانه نظرات خود را در مورد مسائل مختلف مطرح می کنند و آن را در شبکه های اجتماعی منتشر می کنند. ما هر روزه با نظرات افراد مختلف در شبکه های اجتماعی مواجه هستیم. حتما هر کدام از ما تجربه ی خرید اینترنتی را داریم که قبل از خرید به بررسی نظرات افراد مختلف در مورد محصول مورد نظر خود می پردازیم و سپس با بررسی این نظرات محصول مورد نظر خود را انتخاب می کنیم. نظرات حاوی اطلاعات ارزشمندی هستند که می توان با تحلیل آن ها به این دانش ارزشمندی مانند مثبت یا منفی بودن آن نظر در ارتباط با یک موضوع خاص اشاره کرد. این نظرات فقط برای خریداران مهم نیستند بلکه هر کسی از فروشنده و تولید کننده ی محصولات گرفته تا تحلیل گران بازار می توانند از اطلاعات ارزشمند موجود در نظرات بهره ببرند.
به علت اینکه نظرات به صورت متن نوشته می شوند، نظرکاوی از تکنیک های متن کاوی یا پردازش متن برای تحلیل نظرات استفاده می کند. نظرکاوی در سراسر دنیا و به زبان های مختلفی انجام می شود. نظرکاوی کاربردهای فراوانی دارد و روش های مختلفی برای آن توسعه پیدا کرده است. بهتر است در این قسمت به بررسی کاربردهای نظرکاوی بپردازیم تا متوجه شویم چرا نظرکاوی به این اندازه مورد توجه است.
نظرکاوی یا عقیده کاوی یا تحلیل احساسات (opinion mining و sentiment analysis) به کاویدن و تجزیه و تحلیل نظرات افراد با استفاده از تکنیک های زبان شناسی، متن کاوی و پردازش زبان طبیعی اشاره دارد. نظرکاوی می تواند در عرض چند دقیقه متن هزاران صفحه، ایمیل و نظر را تحلیل کند و نتایج را در اختیار کاربر قرار دهد.
تکنیک های نظر کاوی

تکنیک های نظرکاوی می توانند بر روی تعیین قطبیت نظرات (مثبت، منفی یا خنثی)، احساسات فردی (عصبانیت، خوشحالی، ناراحتی و..) و یا هدف آن نظر (راضی یا ناراضی بودن) تمرکز کنند. تکنیک های مختلفی تاکنون برای نظرکاوی توسعه پیدا کرده اند. در ادامه تعدادی از این تکنیک ها را بررسی می کنیم:
نظرکاوی دقیق
متداول ترین کاربرد نظرکاوی، دسته بندی نظرات در سه دسته ی مثبت، منفی و خنثی است. اگر نیاز به تجزیه و تحلیل دقیق تر داشته باشیم می توان آن را در دسته های جزئی تری نیز به صورت دسته بندی کرد:
- خیلی مثبت
- مثبت
- خنثی
- منفی
- خیلی منفی
تشخیص احساس
در تکنیک هایی که به تشخیص احساسات می پردازند، هدف استخراج احساسات مختلف مانند خشم، ناراحتی، خوشحالی، ناامیدی و … است. برخی از روش های تشخیص و شناسایی احساسات از لغت و کلمه های مثبت و منفی استفاده می کنند. اما مشکلی که این روش ها دارند، این است که برخی کلمه ها هم می توانند نشان دهنده ی مثبت بودن نظر باشند و هم منفی.
امروزه روش های مختلفی برای تشخیص احساسات توسعه داده شده اند که مشکلات این چنینی را کاهش می دهد. آن ها می توانند مفهوم جملات را درک کنند و حتی ضرب المثل ها و کنایه ها را در جملات تشخیص داده و تحلیل های دقیق تری ارائه دهند.
نظرکاوی مبتنی بر ویژگی
وقتی که از نظرکاوی برای تحلیل دیدگاه های مشتریان خود نسبت به محصولات استفاده می کنید، ممکن است بخواهید نظرات آن ها را در مورد ویژگی های مختلف کاربرپسند بودن، ارسال محصول، میکروفن، اندازه ی صفحه ی نمایش و … هم بدانید. در این صورت باید مثبت و منفی بودن نظرات مشتریان را در مورد هر یک از این ویژگی ها مشخص شود. برای مثال در نظر “رابط کاربری جدید فوق العاده است” نظر فرد در مورد ویژگی رابط کاربری مثبت است.
نظرکاوی چندزبانه
وقتی که نظرکاوی باید در چند زبان انجام شود، مشکلاتی به همراه دارد. پیش پردازش هایی باید بر روی متن زبان های مختلف انجام شود. واژه های برخی از زبان ها به صورت آنلاین در دسترس است ولی برخی دیگر این گونه نیست و یابد آن ها را جمع آوری نمود. قواعد زبان های مختلف با هم متفاوت است و همه ی این ها مسائلی هستند که در نظرکاوی چند زبانه وجود دارد.
کاربردهای نظرکاوی
هر وقت که تصمیم به خرید محصول می گیریم یا به عنوان یک تولید کننده اقدام به بهبود محصول خود می کنیم و یا به عنوان یک تحلیل گر به بررسی وضعیت بازار محصولات مختلف می پردازیم، از دیگر نظرسنجی می کنیم و مشورت می گیریم. نظرکاوی شامل تکنیک های مختلفی است که این کار را برای ما ساده نموده است. در ادامه به تعدادی از کاربردهای نظرکاوی می پردازیم که هم برای سازمان ها، شرکت ها و هم برای مشتریان و کاربران مفید است.
بازاریابی و هوش تجاری
نظرکاوی نه تنها میتواند دیدگاههای کاربران را جمع آوری، سازمان دهی و خلاصه کند و نتایج را به مشتریان نشان دهد بلکه میتواند برای تولیدکنندهها نیز مفید واقع شود. برای این که شرکت ها بتوانند در بین رقبای خود جایگاه خوبی داشته باشند، باید به طور دقیق، درباره خواستههای مشتریان تحقیق کنند. با به کارگیری نظرکاوی، شرکت ها میتوانند با تحلیل نظرات و دیدگاه های مشتریان، اطلاعاتی را درباره رابطه بین مشتریان و محصولات خود کسب نمایند. کاربران نظرات مثبت و منفی خود را راجب محصول یا خدمت مورد نظر و بخش های مختلف آن بیان کرده اند. تولید کننده ها این اطلاعات را دریافت کرده و در آینده مطابق با این اطلاعات محصولات خود را بهبود می دهند.
همچنین سازمانها می توانند برای بازاریابی محصولات خو نیز از نظرکاوی بهره ببرند. اگر سایت یا شبکه ی اجتماعی وجود داشته باشد که کاربران نسبت به محصول مورد نظر دیدگاه مثبتی داشته باشند، شرکت ها میتوانند بازاریابی خود را در آن ها انجام دهند.
مقایسه محصولات
یک روش معمول برای فروشندگان برخط، دعوت از مشتریان برای بیان دیدگاه خود در مورد محصولی است که خریداری نمودهاند. با افزایش هر چه بیشتر استفاده از وب، تعداد این دیدگاهها روز به روز افزایش مییابد. هر محصول می تواند مزایا و معایبی داشته باشد که توسط افراد مختلف در وب سایتها بیان شود. در این صورت فردی که به دنبال خرید یک محصول است میتوانند مزایا، معایب و تمامی خصوصیات محصولات گوناگون را با هم به طور دقیق مقایسه کند و سپس اقدام به خرید نماید.
علت یابی نظر
در تحلیل نظرات تنها یافتن مثبت و منفی بودن نظر، جمعآوری و خلاصهسازی آنها کافی نیست. میتوان تحلیل عمیق تری نسبت به نظر داشت و به کشف دلیل مثبت یا منفی بودن یک نظر پرداخت. علت یابی نظر به شناسایی یکی از اجزای مهم دیدگاه میپردازد و از این رو سعی در یافتن علت راضی بودن یا نبودن یک فرد نسبت به محصول دارد.
نظرکاوی در زبان فارسی
نظرکاوی در زبان های مختلف از جمله در زبان انگلیسی انجام می شود و روش های مختلفی برای آن توسعه داده شده است. در زبان فارسی هم کارهایی در این زمینه انجام گرفته است. در ادامه قصد داریم یکی از روش هایی که در زبان فارسی برای این کار انجام شده را بررسی کنیم. این روش از یک لغت نامه مشابه با لغت نامه ی Sentiwordnet در زبان انگیسی توسعه پیدا کرده است.
لغت نامه ها بیشتر برای زبان انگلیسی توسعه داده شده اند و لغت نامه ای در زبان فارسی وجود ندارد. هر یک از این لغت نامه ها ساز و کار خاصی را برای تعیین مثبت و منفی بودن دارند. لغت نامه ی انگلیسی SentiWordNet توسعه یافته ی لغت نامه ی WordNet بوده و مقدار قطبیت هر کلمه را به صورت عددی نشان می دهد. در این لغت نامه نقش کلمات و مترادف های آن ها نشان داده شده است. قطبیت در واقع مقدار مثبت و منفی بودن کلمات را نشان می دهد.
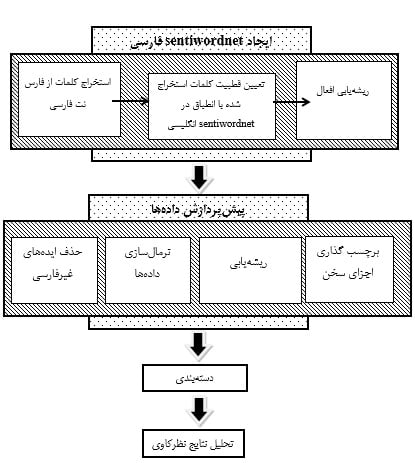
روشی که برای متن کاوی زبان فارسی استفاده شده، ترکیبی از الگوریتم آگاهانه یا با نظارت (supervised) و لغت نامه است. از لغت نامه برای وزن دهی ویژگی ها استفاده شده است. بدین ترتیب می توان تاثیر استفاده از قطبیت را در نظر کاوی تعیین نمود. کلمات مورد استفاده تنها شامل فعل، اسم، صفت و قید می باشند. در نتیجه کلمات دیگر تاثیری در نظرکاوی نخواهند داشت.
چنین لغت نامه ای در زبان فارسی وجود نداشت در نتیجه از SentiWordNet زبان انگلیسی استفاده شده است. همان طور که قبلا اشاره شد SentiWordNet انگلیسی از ورد انگلیسی توسعه پیدا کرده است. برای استفاده از SentiWordNet در زبان فارسی نیاز به وردنت فارسی وجود دارد که خوشبختانه این وردنت در زبان فارسی توسط دانشگاه شهید بهشتی توسعه داده شده است.
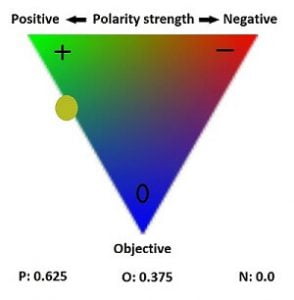
لغت نامه ی SentiWordNet ، قطبیت کلمات را به صورت عددی نشان می دهد و قطبیت هر کلمه، عددی بین ۰ و ۱ است. هر کلمه دارای قطبیت های مثبت، منفی و خنثی است که با یک مقدار عددی نشان داده می شود. حاصل جمع این سه عدد برابر یک می باشد.لغات موجود در وردنت انگلیسی که در آن کلمات به صورت گروه های هم معنی وجود دارند، تعیین قطبیت شده اند و SentiWordNet ایجاد شده است. در SentiWordNet هر کلمه ای دارای معادلی در وردنت انگلیسی است. در واقع کلمات موجود در وردنت انگلیسی همان کلمات موجود در SentiWordNet هستند که تعیین قطبیت شده اند.
در این روش نظرکاوی به زبان فارسی، نظرکاوی در سطح سند انجام می گیرد. به این معنی که هر نظر را به عنوان یک سند در نظر می گیریم. طبق مطالعات انجام گرفته در تحقیقات پیشین الگوریتم SVM برای نظرکاوی نتایج خوبی را بدست آورده است. البته روشهای مختلفی هستند که نتایج خوبی دارند. اما در این نظرکاوی از SVM استفاده شده است. در اینجا مساله ی مهم تر انتخاب ویژگی ها و استخراج آنهاست. همچنین دو الگوریتم بیز و رگرسیون به منظور مقایسه الگوریتم SVM بکار گرفته شده است. نظرکاوی با استفاده از الگوریتم های فوق، نیازمند ویژگی هایی است. در نتیجه باید ویژگی های مورد نیاز استخراج شوند.
گام های نظرکاوی در زبان فارسی
برای استخراج ویژگی دو گام مورد نیاز بود:
• ابتدا تمامی نظرات که به صورت رشته ای از کلمات بودند، تبدیل به برداری از اعداد شدند.
• بعد از استخراج این کلمات، هر کلمه باید تعیین قطبیت شود. هر کلمه به همراه نقش دستوری آن، در لغت نامه قطبیت، مورد جست وجو قرار گرفت. برای هر کلمه ممکن است، چندین نتیجه یافت شود. برای این مسئله، میانگین تمامی نتایج حاصل، به عنوان قطبیت در نظر گرفته شد. در نتیجه در طی این مرحله تمامی ویژگی ها تعیین قطبیت می شوند. از بین این کلمات، اسم ها، فعل ها، صفات و قید تعیین قطبیت شدند و سایر موارد از جمله حروف و اعداد که دارای قطبیت نیستند، قطبیت صفر گرفتند.
ایجاد لغت نامه در زبان فارسی برای نظرکاوی
در این نظرکاوی، از نسخه ی دوم وردنت فارسی به نام فارس نت استفاده شده است. در طی سه گام این لغت نامه ایجاد شد:
در گام اول تمامی کلمات موجود در وردنت مورد جست وجو قرار گرفتند. همه کلمات موجود دارای معادل انگلیسی نیستند. برای ایجاد لغت نامه به کلماتی نیاز داریم که دارای معادل در وردنت انگلیسی باشند. از این بین، ۱۵۸۵۸ گروه هم معنی، که دارای معادل بودند، استخراج شدند. بیشتر گروه های استخراج شده دارای یک معادل انگلیسی بودند، ولی گروه هایی هم وجود داشتند که بیش از یک معادل داشتند. برای مثل کلمه “خوب” در فارس نت دارای سه معادل در وردنت انگلیسی است.
در گام دوم، تمانی این گروه های استخراج شده، در SentiWordNet انگلیسی مورد جست وجو قرار گرفتند تا قطبیت هر کلمه تعیین گردد. همان طور که قبلاً اشاره شد، هر کلمه موجود در وردنت انگلیسی دارای معادلی در SentiWordNet انگلیسی است. در نتیجه با جستجوی کلماتی که در مراحل قبل استخراج شدند، می توان قطبیت هر کلمه را تعیین نمود. برای کلماتی که شامل چندین معادل در وردنت انگلیسی هستند، تمامی معادل ها در SentiWordNet شناسایی شدند و سپس از میانگین تمامی معادل ها برای قطبیت آن کلمه استفاده شد. برای مثال کلمه “خوب”، دارای سه معادل انگلیسی است. برای این کلمه، قطبیت هر سه معادل شناسایی شده و قطبیت کلمه “خوب” برابر میانگین قطبیت های این سه کلمه در نظر گرفته شد.
افعال استخراج شده از وردنت، به شکل مصدر استخراج شدند. در نتیجه نیاز به یافتن ریشه کلمات بود. از ابزار پردازش زبان طبیعی، برای این منظور استفاده شد.
مشکلات نظرکاوی در زبان فارسی
متن کاوی در زبان فارسی برخلاف زبان انگلیسی دارای پیچیدگی های بیشتری است. این پیچیدگی به دلیل کمبود ابزار و راه های مختلف، وجود پسوندهای متفاوت، فاصله گذاری کلمه ها و استفاده از کلمه های غیر رسمی و محاوره ای ایجاده شده است.
• عدم وجود ابزار مناسب برای زبان فارسی
• کلمات غیررسمی و محاوره ای
• وجود پسوندهای متفاوت برای صرف افعال
• فاصله گذاری (فاصله و نیم فاصله)